Ich spreche, Obsidian schreibt – Sprachmemos via Telegram, Whisper & n8n.
Table of Contents
Ich stehe auf dem Spielplatz. Zwei Kinder klettern auf dem Klettergerüst herum, eine Kindergartenmutter, ein Kindergartenvater und ich reden über Kings of Convenience. Über The Weight of my Words. Über das Album Versus. Über die Zeit, als Musik noch wehtat, weil man jung und etwas unfertig war.
Und dann ist der Moment weg. Die Kinder rufen. Man geht nach Hause. Und diese kleine, kostbare Erinnerung bleibt irgendwo auf der Strecke zwischen Spielplatz und Kühlschrank.
Nicht mehr. Weil ich jetzt einfach mein Handy raushole, Telegram öffne, auf Aufnahme drücke – und alles von alleine weiterläuft.
Das Problem: Gedanken verdampfen
Ich habe schon lange mit Obsidian als zweites Gehirn gearbeitet. Das Problem: Ein zweites Gehirn nützt nichts, wenn man zu faul ist, es zu füttern. Tippen am Spielplatz? Nein danke. Eine Notiz-App öffnen, eintippen, Markdown formatieren? Auch nein. Ich bin ein Mensch, der spricht. Also musste die Lösung auch mit Sprache funktionieren.
Die Idee war simpel: Ich schicke eine Sprachnachricht an einen Telegram-Bot. Der Rest passiert automatisch. Das Ergebnis landet als fertige .md-Datei in meinem Obsidian Vault – dank Nextcloud-Sync. Magic.
Die Zutaten
Bevor ich in die Details gehe, kurz der Überblick was ich hier eigentlich zusammengebaut habe:
- Telegram Bot – mein mobiles Mikrofon
- n8n – der Kleber, der alles zusammenhält (selbst gehostet, natürlich)
- faster-whisper-server – ein lokaler KI-Transkriptions-Dienst, der Deutsch kann und keine Cloud braucht
- Nextcloud – mein selbst gehosteter Cloudspeicher, der mit Obsidian synchronisiert
- Obsidian – das Endlager für alle meine Gedanken
Kein Abo. Keine Cloud. Keine Datenschutzbedenken. Alles läuft zuhause.
Schritt 1: Whisper lokal betreiben
Der erste Baustein ist ein lokaler Whisper-Server. Ich nutze dafür das Docker-Image fedirz/faster-whisper-server – eine schnelle, OpenAI-API-kompatible Implementierung, die auf normaler CPU läuft.
Mein docker-compose.yml:
┌─────────────────────────────────────────────────────────────────┐
│ docker-compose.yml │
├─────────────────────────────────────────────────────────────────┤
│ services: │
│ whisper-api: │
│ image: fedirz/faster-whisper-server:latest-cpu │
│ container_name: whisper-api │
│ environment: │
│ - WHISPER__MODEL=Systran/faster-whisper-small │
│ volumes: │
│ - whisper_cache:/root/.cache/huggingface │
│ ports: │
│ - "5092:8000" │
│ networks: │
│ - home_default │
│ restart: unless-stopped │
│ │
│ volumes: │
│ whisper_cache: │
│ │
│ networks: │
│ home_default: │
│ external: true │
└─────────────────────────────────────────────────────────────────┘
Das Model faster-whisper-small ist der Sweet Spot: klein genug für ältere Hardware, gut genug für Sprache auf Deutsch. Beim ersten Start lädt Docker das Hugging-Face-Modell herunter und cached es im Volume – danach ist alles offline.
$ docker compose up -d
[+] Running 2/2
✔ Volume "whisper_cache" created
✔ Container whisper-api started
$ curl http://localhost:5092/v1/models
{
"data": [
{ "id": "Systran/faster-whisper-small", "object": "model" }
]
}
Der Server ist jetzt erreichbar unter http://192.168.178.118:5092 und versteht die OpenAI-kompatible API. Heißt: alles, was mit whisper-1 umgehen kann, kann auch meinen lokalen Server ansprechen.
Schritt 2: Der n8n-Workflow
Jetzt kommt n8n ins Spiel – mein selbst gehostetes Automatisierungsgehirn. Der Workflow hat genau sechs Schritte, und sieht so aus:
┌─────────────────────────────────────────────────────────────────────────────┐
│ n8n Workflow: Telegram → Memo │
├──────────────────┐ │
│ Telegram │ Sprachnachricht kommt rein (voice message) │
│ Trigger ───────┼──────────────────────────────────────────────────────► │
│ (Bot: Memo) │ │
└──────────────────┘ │
│ │
▼ │
┌──────────────────┐ │
│ Get a file │ Telegram-API: Audiodatei (.ogg) herunterladen │
│ (Telegram) │ → fileId aus message.voice.file_id │
└──────────────────┘ │
│ │
▼ │
┌──────────────────┐ │
│ HTTP Request │ POST → http://192.168.178.118:5092/v1/audio/ │
│ (Whisper API) │ transcriptions │
│ │ Body: multipart/form-data │
│ │ model=whisper-1 │
│ │ file=<audio binary> │
└──────────────────┘ │
│ │
▼ │
┌──────────────────┐ │
│ Code in JS │ Hashtags aus dem transkribierten Text entfernen │
│ │ text.replaceAll("Hashtag ", "#") │
└──────────────────┘ │
│ │
▼ │
┌──────────────────┐ ┌──────────────────────────────────────────────────┐ │
│ Upload .md │ │ Upload .ogg │ │
│ (Nextcloud) │ │ (Nextcloud) │ │
│ Notizen/Memos/ │ │ Notizen/Memos/ │ │
│ YYYY-MM-DD │ │ YYYY-MM-DD_<updateId>.ogg │ │
│ HH-mm-ss.md │ └──────────────────────────────────────────────────┘ │
└──────────────────┘ │
│ │
▼ │
┌──────────────────┐ │
│ Send a text │ Transkription zurück an Telegram senden │
│ message │ → Bestätigung, dass alles geklappt hat │
└──────────────────┘ │
└─────────────────────────────────────────────────────────────────────────────┘

Node 1: Telegram Trigger
Ein einfacher Webhook-Trigger, der auf eingehende Nachrichten des Bots „Memo" wartet. Sobald eine Sprachnachricht ankommt, feuert der Workflow.
Node 2: Get a file
Telegram gibt uns nur die file_id der Sprachdatei. Mit diesem Node holen wir uns die eigentliche .ogg-Datei via Telegram-API herunter. Der Ausdruck $json.message.voice.file_id liefert den richtigen Wert.
Node 3: HTTP Request → Whisper
Das ist das Herzstück. Wir schicken einen POST-Request an unseren lokalen Whisper-Server:
POST http://192.168.178.118:5092/v1/audio/transcriptions
Content-Type: multipart/form-data
model=whisper-1
file=<binary audio data>
Zurück kommt JSON mit dem transkribierten Text. Auf Deutsch, offline, auf meinem eigenen Server.
Node 4: Code in JavaScript
Whisper transkribiert manchmal das Wort „Hashtag" wörtlich, wenn ich aufzähle. Ein schneller Einzeiler bereinigt das:
for (const item of $input.all()) {
let text = item.json.text;
text = text.replaceAll("Hashtag ", "#");
item.json.text = text;
}
return $input.all();
Super gut, weil ich dann auch nach den inline Tags in Obsidian suchen kann, ohne manuell nachzubessern.
Node 5 & 6: Upload zu Nextcloud
Zwei parallele Uploads gehen raus:
- Die Markdown-Datei – Pfad:
Notizen/Memos/YYYY-MM-DD HH-mm-ss.md - Die Originalaudio-Datei – Pfad:
Notizen/Memos/YYYY-MM-DD_<updateId>.ogg
Der Dateiinhalt der .md-Datei sieht so aus:
Memo vom 29.03.2026
Letztens habe ich mich auf dem Spielplatz mit einer Kindergartenmutter
und einem Kindergartenvater unterhalten. Da ging es um unsere alte Musik,
die Musik, die wir früher gehört haben...
---
![[2026-03-29 617268880.ogg]]
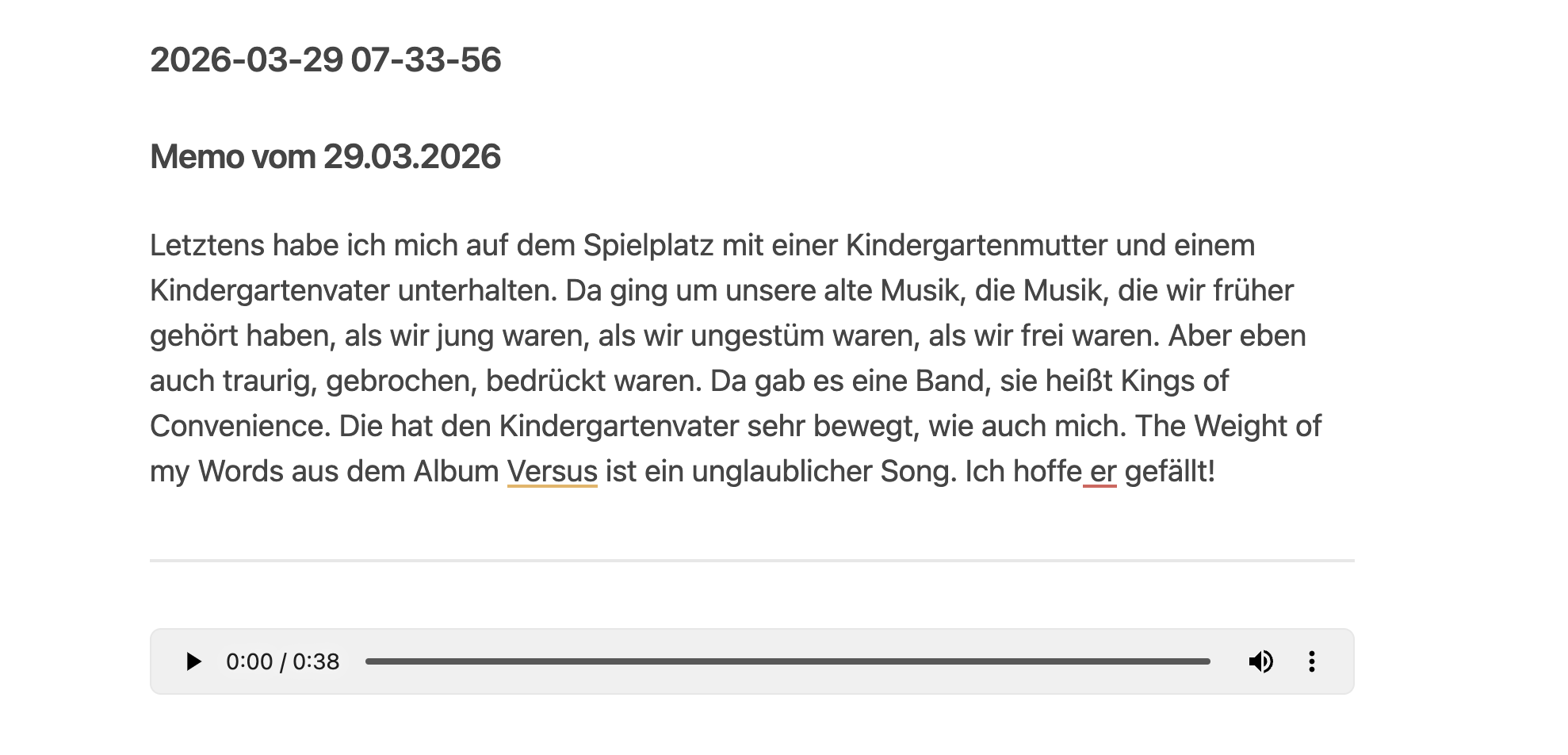
Der Timestamp kommt aus now.toUTC().format('dd.MM.yyyy') direkt in n8n – kein manuelles Datum mehr.
Node 7: Bestätigung zurück an Telegram
Als letzten Schritt schickt der Workflow den transkribierten Text zurück an meinen Telegram-Chat. So sehe ich sofort: Hat Whisper mich richtig verstanden? Oder hat es aus „Kings of Convenience" irgendwas wie „Königs von Konvenienz" gemacht? (Hat es nicht. Ich bin beeindruckt.)
Schritt 3: Nextcloud ↔ Obsidian
Das Schöne an diesem Setup: Nextcloud und Obsidian kennen sich schon. Ich habe den Ordner Notizen/Memos/ in meinem Nextcloud als synchronisierten Pfad eingerichtet. Sobald n8n die .md-Datei hochlädt, landet sie binnen Sekunden in meinem Obsidian Vault – auf Desktop und Handy.
Nextcloud (Server)
└── Notizen/
└── Memos/
├── 2026-03-29 12-27-03.md ← Transkript als Markdown
└── 2026-03-29 617268880.ogg ← Originalaudio zum Nachhören
In Obsidian sieht das dann fertig aus – mit Datum im Titel, dem vollen Text und einem Link zur Audiodatei darunter. Ich muss nichts anfassen. Nichts formatieren. Nichts umbenennen.
Das Ergebnis
Ich stehe wieder auf dem Spielplatz. Das Gespräch endet. Ich halte kurz mein Handy hoch, drücke auf Aufnahme im Telegram-Bot, spreche 30 Sekunden – und gehe dann einfach nach Hause.
Irgendwo in meinem Heimnetzwerk passiert gerade Folgendes:
[Telegram] → Sprachnachricht empfangen (617268880)
[n8n] → .ogg heruntergeladen (128 KB)
[Whisper] → Transkription gestartet...
[Whisper] → Fertig in 2.3s: "Letztens habe ich mich auf dem Spielplatz..."
[Nextcloud] → 2026-03-29 12-27-03.md hochgeladen ✓
[Nextcloud] → 2026-03-29 617268880.ogg hochgeladen ✓
[Telegram] → Bestätigung gesendet ✓
Und das alles ohne einen einzigen Cloud-Dienst von Drittanbietern. Kein OpenAI-API-Key. Keine Abo-Kosten. Kein „Ihre Sprachdaten helfen uns, unsere Dienste zu verbessern."
Kings of Convenience – The Weight of my Words. Jetzt hat auch das Gewicht meiner Worte endlich einen Platz gefunden.
Danke, J.!
Wer meinen Blog schon länger liest, kennt J. – meinen Freund, der mich in epische Rabbit Holes schubst und dann unschuldig guckt. Diesmal hat er mir Parakeet von NVIDIA vorgeschlagen, ein sehr schnelles Speech-to-Text-Modell, das ich mir auch ernsthaft angeschaut habe.
Das Problem: Telegram schickt Sprachnachrichten im Ogg-Vorbis-Format (.ogg) – und Parakeet mag kein Vorbis. Man könnte das Audio vorher konvertieren, aber ehrlich gesagt wollte ich keinen weiteren Umwandlungsschritt in den Workflow bauen. Whisper hingegen schluckt Ogg klaglos, ohne mit der Wimper zu zucken.
Also: J., danke für den Tipp. Du hattest wieder eine gute Idee. Ich habe sie nur ein kleines bisschen verbogen – wie immer.